
与AI相识
事件的起源
stable diffusion之源
AI绘图最初是由于包括DALLE2、MidJourney、Disco diffusion、DreamStudio、Stable Diffusion在内的一些AI绘画网站的出现,引发了AI绘画的热潮,最让此事更进一步的可以说是开源可商用并且生成速度迅速的SD。
Stable diffusion中文名:稳定扩散,这里再提一嘴Latent diffusion(潜在扩散),他们的关系是什么:
源自wiki:
Stable Diffusion uses a kind of diffusion model (DM), called a latent diffusion model (LDM)
Stable Diffusion是一种潜在的 扩散模型是慕尼黑大学CompVis 小组开发的一种深度生成神经网络。该模型由 Stability AI、CompVis LMU 和 Runway 在 EleutherAI 和LAION的支持下合作发布。
笔者可以理解为团队中取自stabilityAI的stable之名,其算法源自于早些年论文提出的潜在模型算法。
Stable Diffusion 算法上来自 CompVis 和 Runway 团队于 2021 年 12 月提出的 “潜在扩散模型”(LDM / Latent Diffusion Model),这个模型又是基于 2015 年提出的扩散模型(DM / Diffusion Model)。
说句题外话,我非常想知道为什么 Stable Diffusion 叫 Stable Diffusion,但没找到官方说明,这里做一个猜测:之所以这个基于 Latent Diffusion的模型叫 Stable Diffusion,可能一方面表示这个模型效果很稳定(Stable),另一方面是致敬一下(算力 & 数据上的)金主爸爸 Stability.ai。
潜在模型算法

总的来说,分为三个模块:CLIP、Unet和VAE
如果让计算机对512x512分辨率的rgb图片进行学习,那么其维度将会是512x512x3也就是786432维度,计算机面对如此庞大的数据进行学习将会对算力性能有极高的要求。而正是潜在模型算法的提出和实现使得这种AI学习技术飞入寻常百姓家。
团队人员提出,如果将图片的信息进行压缩,使其映射到一个“潜在空间”,那么将会使得计算机的学习非常方便和迅速。
AI 就是通过学习找到了一个「图片潜在空间」,每张图片都可以对应到其中一个点,相近的两个点可能就是内容、风格相似的图片。

所以常说的xyz轴其实就表示了潜在空间。
CLIP (对比式语言-文字预训练)
Contrastive Language-Image Pre-Training。
将文字和图片一同训练,将会得到二者潜在空间的映射关系,如下图:
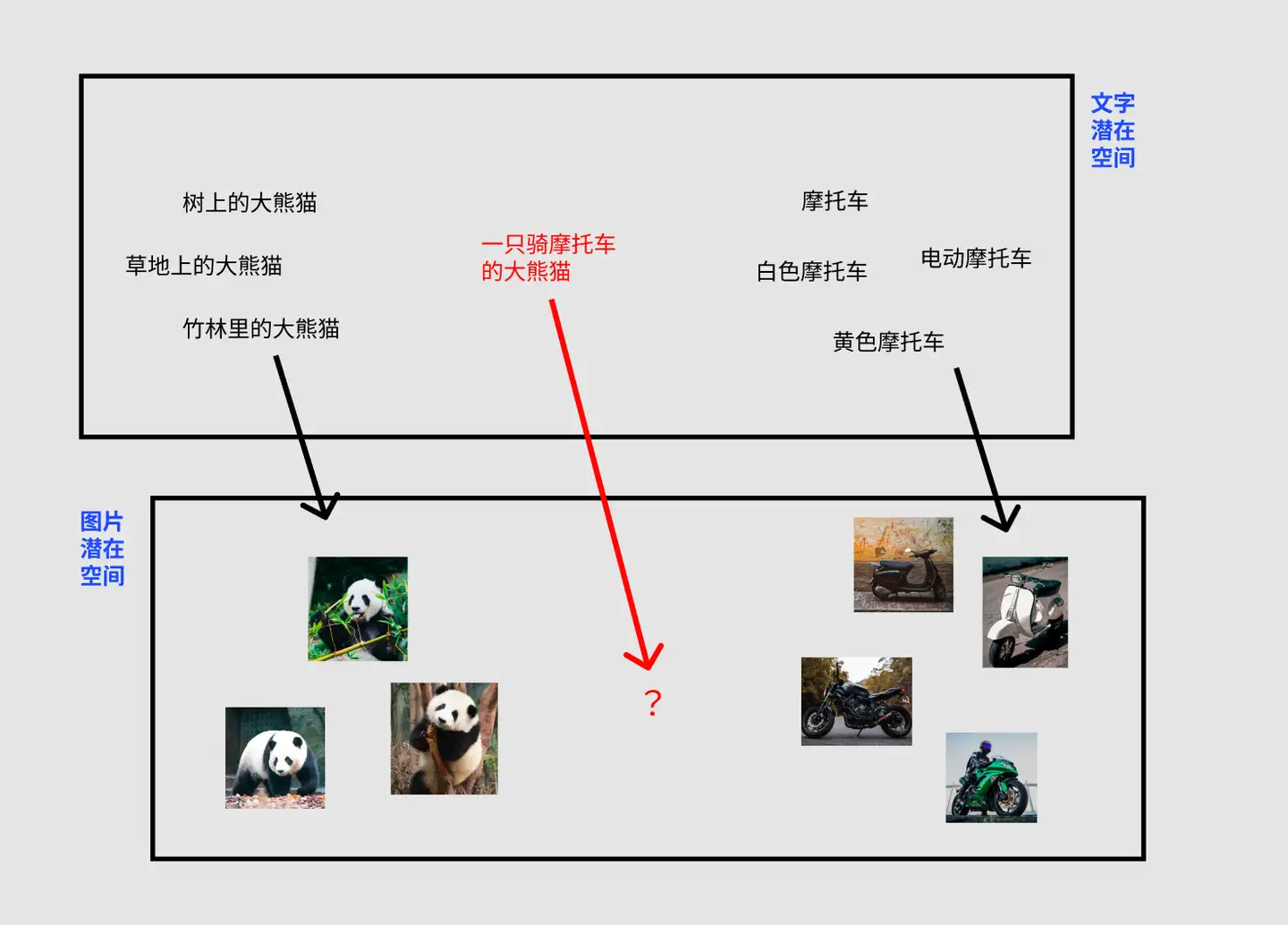
文本编码器是一种Transformer语言模型,作为语言理解组件,接收文本提示,生成词嵌入。发布的Stable Diffusion模型使用ClipText(基于GPT的模型),而论文中使用BERT。
要了解Text Encoder,首先简单介绍一下CLIP这个模型。该模型的训练集由 4 亿张图像及其描述组成,训练时分别对图像和文本进行编码,然后,使用余弦相似度比较生成的嵌入。**通过训练最终使编码器能够生成图像和描述相似的嵌入。**总结起来如下图所示:
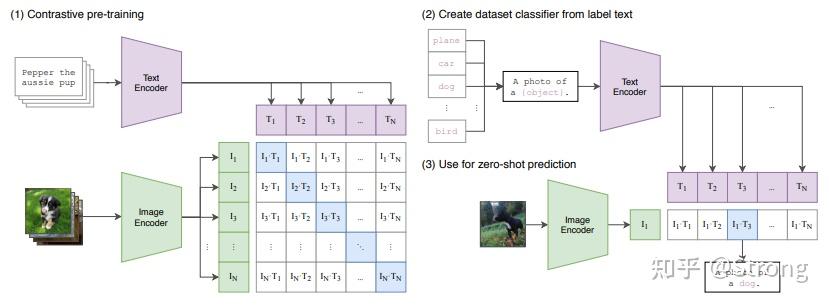
可以看出图中标蓝色的矩阵对角线都是正样本,其他的就是负样本。实际推理预测的时候,新的图像来了,经过image encoder得到图片嵌入向量,将该向量和所有label文本生成的嵌入向量求一个softmax就可以得到该图片分属于哪一个label文本,从而完成该图片的分类。整体过程还是比较简单清晰的。
画手:Unet模型
前向过程
Creator代表扩散模型的反向过程。这里,我们先了解以下扩散模型的前向过程。所谓前向过程,即往图片上加噪声的过程。考虑向一个从真实数据分布中随机采样的变量添加噪声,添加T次之后,会得到一个长度为T的序列,随着T的增大,原始数据会丢失它的特征而变成一个纯的高斯噪声。
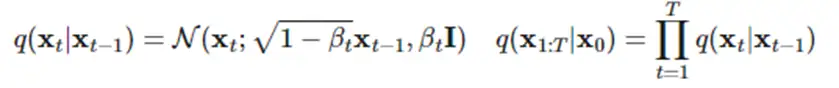
在这个过程中,每个时刻t只与t-1时刻有关,所以可以看作一个马尔可夫过程。
虽然xt只与xt-1相关,但是通过独立高斯分布性质和重参数化技巧,经过推导,可以得到一个xt关于x0的关系:

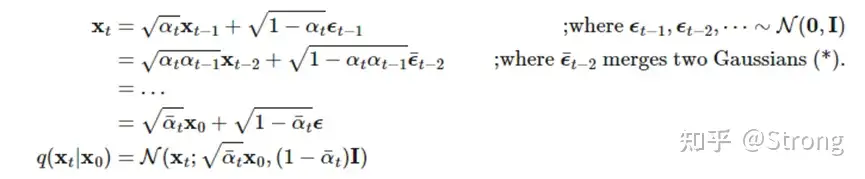
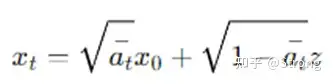
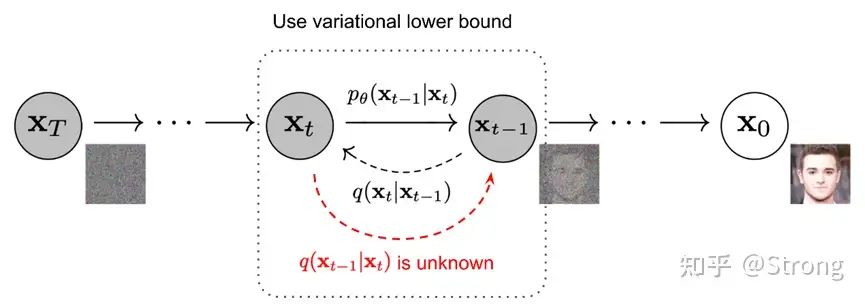
反向过程
反向过程就是去噪的过程。知道xt来计算xt-1。但是我们对于q(xt-1|xt)是不知道的,最好是可以通过推导,得到一个xt-1关于xt的关系。通过贝叶斯法则,可以推导:
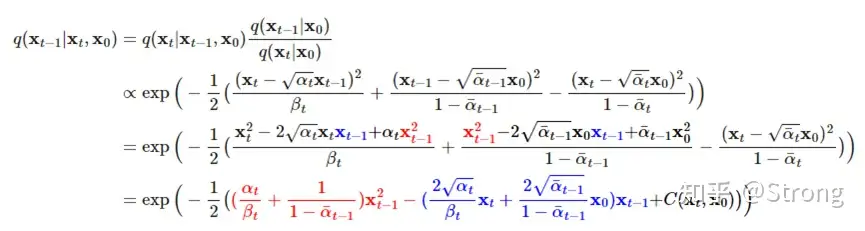
可以看到,经过推导变成了我们正向过程中已经可以表达的关系。但是反向过程中我们对于x0也是不知道的。但根据正向中xt与x0的关系,我们可以把x0进行替换,最终得到只与xt和一个未知的ε的关系:
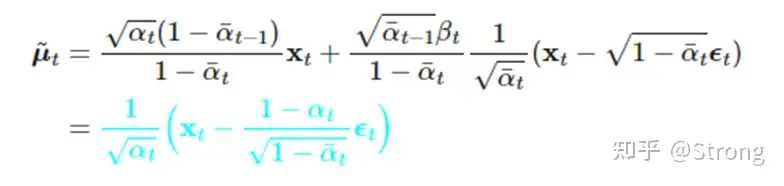
至于这个未知的ε,使用深度学习模型(unet,或者最新的DiT论文中用transformer模块来替代unet)来进行预测。
总结起来,creator的每一步推断就是执行下面的算法流程:
1)使用深度学习模型(unet),通过xt和t来预测高斯噪声zθ(xt,t),然后根据公式计算均值和方差:
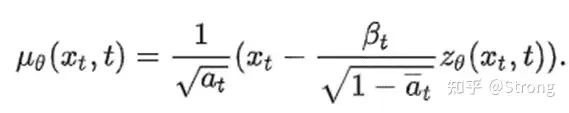
2) 根据公式得到p(xt-1|xt):
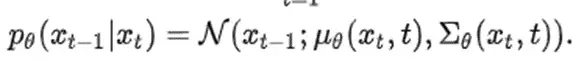
3)利用重参数化得到xt-1,重参数化可表示为可求导的分布随机采样。
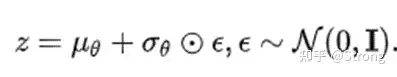
其中⊙表示element-wise乘。
VAE是什么?
VAE (Variational Auto-Encoder 变分自动编码器)模型有两部分,分别是一个编码器和一个解码器,常用于AI图像生成
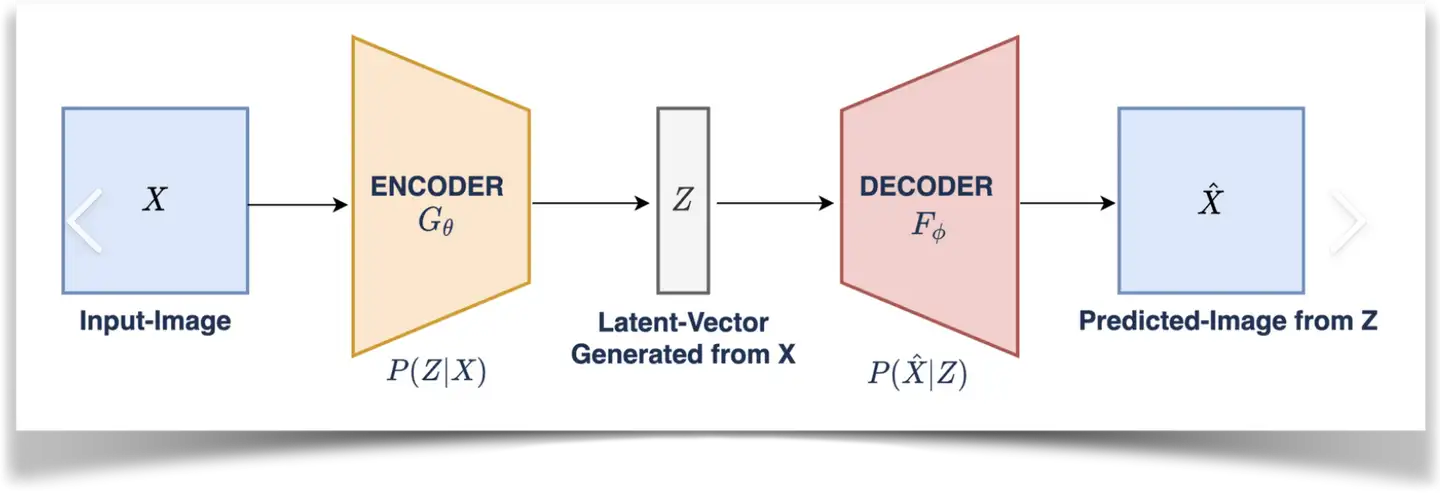
在潜在扩散模型(Latent Diffusion Models)组成中就有VAE模型的身影。
stable diffusion 模型推理流程图:
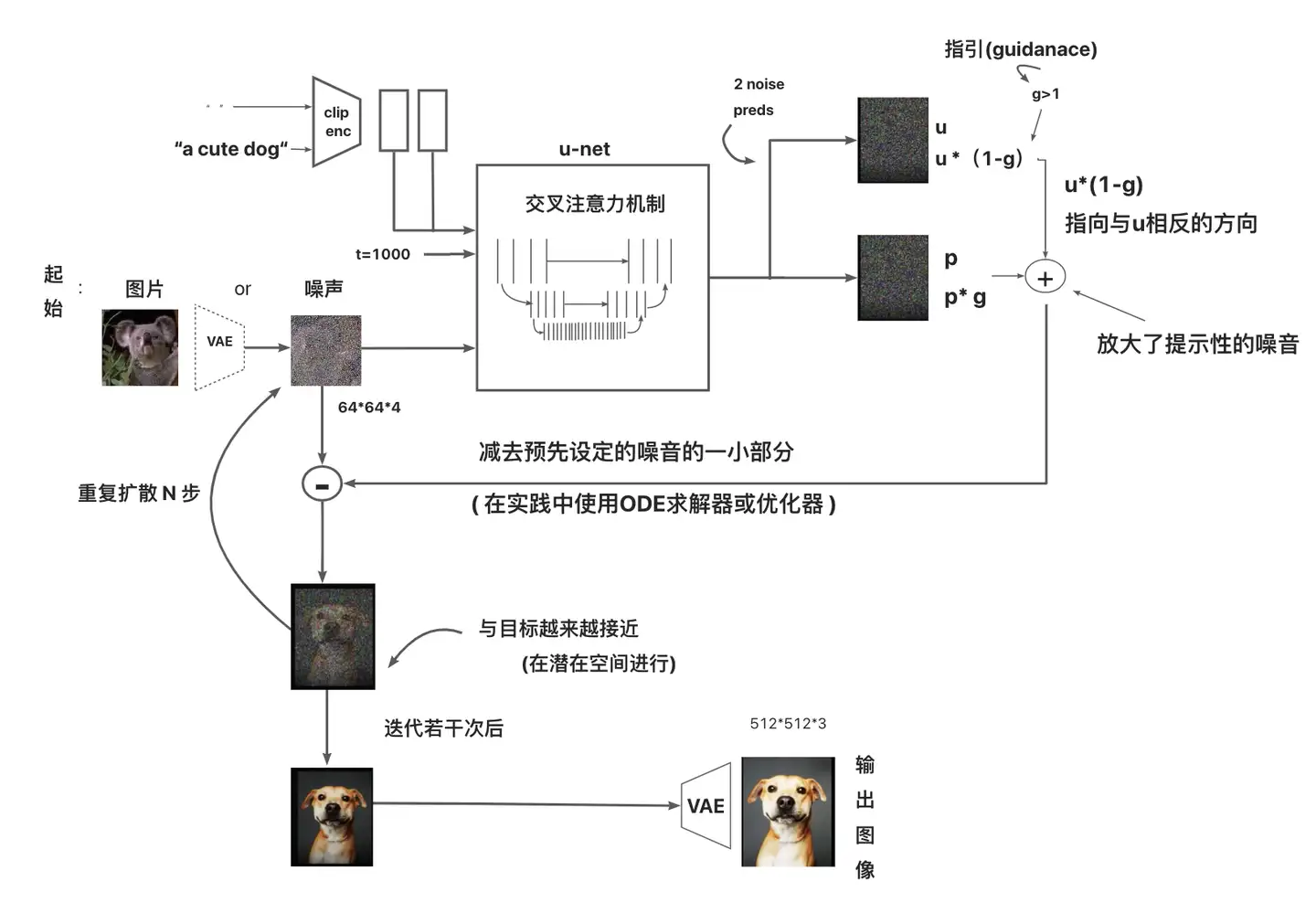
其中**编码器(encoder)**被用于把图片转换成低维度的潜在表征,转换完成后的潜在表征将作为U- Net 模型的输入。
反之,**解码器(decoder)**将把潜在表征重新转回图片形式。
在潜在扩散模型的训练过程中,编码器被用于取得图片训练集的潜在表征(latents),这些潜在表征被用于前向扩散过程(每一步都会往潜在表征中增加更多噪声)。
在推理生成时,由反向扩散过程生成的 denoised latents 被VAE 的解码器部分转换回图像格式。
所以说 ,在潜在扩散模型的推理生成过程中我们只需用到VAE的解码器部分。
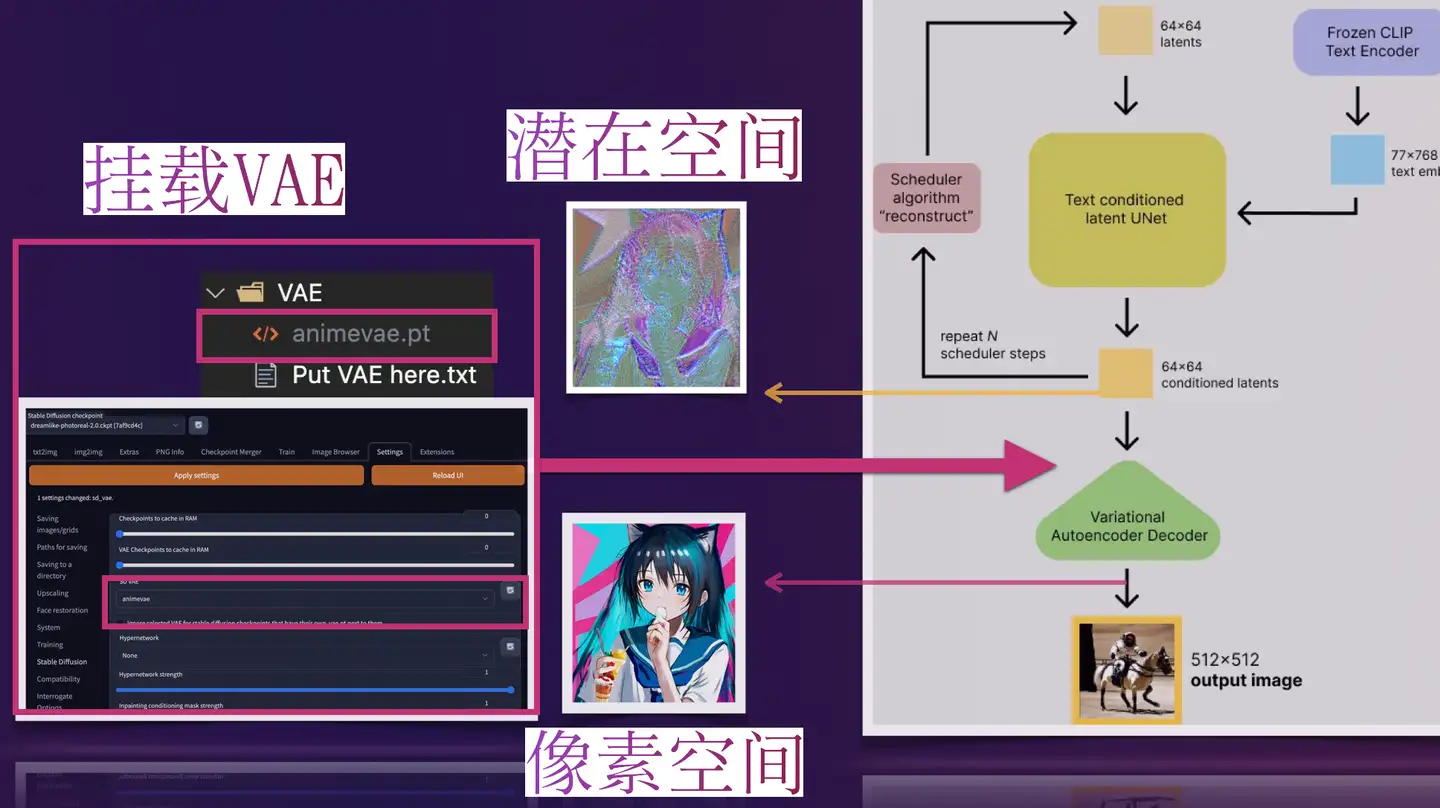
WebUI中的VAE
那些比较流行预训练的模型一般都是内置了训练好的VAE模型的,不用我们再额外挂载也能做正常的推理生成(挂载后生成图像的效果会有一点点细微的区别),此时VAE pt文件的作用就像HDR ,增加一点点图片色彩空间之类的一些自定义模型。
可如果一些预训练模型文件不内置VAE(或训练他们自己的VAE,此时通常会在他们的模型发布说明中告诉你从哪得到他们的VAE)。我们就必须给它找一个VAE挂载上去,用来将推理时反向扩散最后生成的 denoised latents 转换回图像格式,否则webui里最后生成输出给我们的就是类似彩噪的潜在表征(latents),此时VAE pt文件的作用就像解压软件 ,为我们解压出肉眼友好可接受的图像。
做了张图来直观地说明展示下:
运行Stable diffusion项目
在网络上还没有这么多搭建项目的教程之前,笔者是通过无UI的方式跑起的SD,当时尝试了各种方法都多多少少有问题,最多出现的问题是早些时各种模型项目之间依赖项的版本有冲突,还有的就是国内网络的问题。
笔者最终使用的是bentoml的框架连同其打包的SD,记得当时是1.4版本。不过后来bentoml就没有在其github上更新过项目,笔者后续手动更新了SD的模型版本。
今年年初左右,github上webui那位最高星作者(AUTOMATIC1111)的项目走向成熟。规范化目录结构,提供WebUI,文件保存启动参数,丰富的参数调节以及插件支持等。
SD同时也走向的最火时期,网络上出现了各种搭建教程以及训练模型,仿佛引发了链式反应,AI绘图界欣欣向荣,人人都可以参与到这场盛宴中。b站秋叶up主甚至开发了Win系统上的SD-WebUI启动器,可以一键部署、提供了可视化管理页面、版本管理,并且非常方便的下载和管理模型。
笔者使用的是无GUI版本的Linux,不过up主秋叶提供了非常多的信息可以帮助更好的学习。
Linux环境下SD-WebUI的搭建
- 新建python3.10.6的conda环境:
conda create -n py3106 python=3.10.6- 进入conda环境
conda initconda activate py3106- 克隆项目
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git如果git下载出错采用
git config --global http.postBuffer 5242880000git config --global https.postBuffer 5242880000git config --global http.sslverify "false"或者采用git镜像 kgithub
全局:(慎用)
git config --system url."https://kgithub.com/".insteadOf https://github.com/- root权限下关闭限制:修改webui.sh
# this script cannot be run as root by defaultcan_run_as_root=1- 运行webui.sh
bash webui.sh --listen --port 9099期间会下载依赖和模型,如果下载出错,可以去launch.py中尝试把github.com改成kgithub.com
启动参数:
usage: launch.py [-h] [--data-dir DATA_DIR] [--config CONFIG] [--ckpt CKPT] [--ckpt-dir CKPT_DIR] [--vae-dir VAE_DIR] [--gfpgan-dir GFPGAN_DIR] [--gfpgan-model GFPGAN_MODEL] [--no-half] [--no-half-vae] [--no-progressbar-hiding] [--max-batch-count MAX_BATCH_COUNT] [--embeddings-dir EMBEDDINGS_DIR] [--textual-inversion-templates-dir TEXTUAL_INVERSION_TEMPLATES_DIR] [--hypernetwork-dir HYPERNETWORK_DIR] [--localizations-dir LOCALIZATIONS_DIR] [--allow-code] [--medvram] [--lowvram] [--lowram] [--always-batch-cond-uncond] [--unload-gfpgan] [--precision {full,autocast}] [--upcast-sampling] [--share] [--ngrok NGROK] [--ngrok-region NGROK_REGION] [--enable-insecure-extension-access] [--codeformer-models-path CODEFORMER_MODELS_PATH] [--gfpgan-models-path GFPGAN_MODELS_PATH] [--esrgan-models-path ESRGAN_MODELS_PATH] [--bsrgan-models-path BSRGAN_MODELS_PATH] [--realesrgan-models-path REALESRGAN_MODELS_PATH] [--clip-models-path CLIP_MODELS_PATH] [--xformers] [--force-enable-xformers] [--xformers-flash-attention] [--deepdanbooru] [--opt-split-attention] [--opt-sub-quad-attention] [--sub-quad-q-chunk-size SUB_QUAD_Q_CHUNK_SIZE] [--sub-quad-kv-chunk-size SUB_QUAD_KV_CHUNK_SIZE] [--sub-quad-chunk-threshold SUB_QUAD_CHUNK_THRESHOLD] [--opt-split-attention-invokeai] [--opt-split-attention-v1] [--opt-sdp-attention] [--opt-sdp-no-mem-attention] [--disable-opt-split-attention] [--disable-nan-check] [--use-cpu USE_CPU [USE_CPU ...]] [--listen] [--port PORT] [--show-negative-prompt] [--ui-config-file UI_CONFIG_FILE] [--hide-ui-dir-config] [--freeze-settings] [--ui-settings-file UI_SETTINGS_FILE] [--gradio-debug] [--gradio-auth GRADIO_AUTH] [--gradio-auth-path GRADIO_AUTH_PATH] [--gradio-img2img-tool GRADIO_IMG2IMG_TOOL] [--gradio-inpaint-tool GRADIO_INPAINT_TOOL] [--opt-channelslast] [--styles-file STYLES_FILE] [--autolaunch] [--theme THEME] [--use-textbox-seed] [--disable-console-progressbars] [--enable-console-prompts] [--vae-path VAE_PATH] [--disable-safe-unpickle] [--api] [--api-auth API_AUTH] [--api-log] [--nowebui] [--ui-debug-mode] [--device-id DEVICE_ID] [--administrator] [--cors-allow-origins CORS_ALLOW_ORIGINS] [--cors-allow-origins-regex CORS_ALLOW_ORIGINS_REGEX] [--tls-keyfile TLS_KEYFILE] [--tls-certfile TLS_CERTFILE] [--server-name SERVER_NAME] [--gradio-queue] [--skip-version-check] [--no-hashing] [--no-download-sd-model] [--addnet-max-model-count ADDNET_MAX_MODEL_COUNT] [--controlnet-dir CONTROLNET_DIR] [--no-half-controlnet] [--dreambooth-models-path DREAMBOOTH_MODELS_PATH] [--lora-models-path LORA_MODELS_PATH] [--ckptfix] [--force-cpu] [--profile-db] [--debug-db] [--ldsr-models-path LDSR_MODELS_PATH] [--lora-dir LORA_DIR] [--scunet-models-path SCUNET_MODELS_PATH] [--swinir-models-path SWINIR_MODELS_PATH]运行报错,without xformers,解决办法:
带上--xformers启动参数,python3.10环境会自动下载安装无需编译
commandline_args = os.environ.get('COMMANDLINE_ARGS', "--xformers")采用人脸修复模型时 codeformer/gfpgan会下载对应模型,如果下载中断报错,手动下载到/models/xxx/
codeformer:
wget https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth缺少libgl报错
apt updateapt install libgl1-mesa-glxapt install libglib2.0-dev- 设置中文,下载插件报错,重新运行服务,运行时命令行添加arg:
--enable-insecure-extension-access:
--listen --port 9099 --enable-insecure-extension-access --xformers下载失败:
手动下载:/extensions/
cd /extensionsgit clone https://kgithub.com/dtlnor/stable-diffusion-webui-localization-zh_CN.git设置 user interface localization -> zh
apply,reload webui
-
下载controlnet插件
修改设置中的yaml的目录
错误处理
-
若原来没有问题,某次开始启动过程中若出现报错,请排查安装某个插件的原因。
怀疑是某个插件修改了python包中的文件,尝试移除venv文件夹,并且切换至conda python3.10.6环境重新运行webui.sh,这将重新自动生成venv虚拟环境。
-
如果你确定项目依赖没有问题,但是每次启动时又会检测依赖花费很长时间,那么可以在launch.py文件中找到以下一行并注释掉:
run_pip(f"install -r {requirements_file}", "requirements for Web UI") -
启动了—listen arg后插件的操作将会被影响,如果希望可信用户操作插件,请使用
--enable-insecure-extension-accessarg。 -
出现报错:
Warning: StyleAdapter and cfg/guess mode may not works due to non-batch-cond inference
运行程序的一些命令行参数及解释
| 命令行参数 | 解释 |
|---|---|
| —share | online运行,也就是public address |
| —listen | 使服务器侦听网络连接。这将允许本地网络上的计算机访问UI。 |
| —port | 更改端口,默认为端口7860。 |
| —xformers | 使用xformers库。极大地改善了内存消耗和速度。Windows 版本安装由C43H66N12O12S2 维护的二进制文件。牺牲图片质量换取节省vram。 |
| —force-enable-xformers | 无论程序是否认为您可以运行它,都启用 xformers。不要报告你运行它的错误。 |
| —opt-split-attention | Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
| —disable-opt-split-attention | 禁用上面的优化 |
| —opt-split-attention-v1 | 使用上述优化的旧版本,它不会占用大量内存(它将使用更少的 VRAM,但会限制您可以制作的最大图片大小)。 |
| —medvram | 通过将稳定扩散模型分为三部分,使其消耗更少的VRAM,即cond(用于将文本转换为数字表示)、first_stage(用于将图片转换为潜在空间并返回)和unet(用于潜在空间的实际去噪),并使其始终只有一个在VRAM中,将其他部分发送到CPU RAM。降低性能,但只会降低一点-除非启用实时预览。 |
| —lowvram | 对上面更彻底的优化,将 unet 拆分成多个模块,VRAM 中只保留一个模块,破坏性能。 |
| —do-not-batch-cond-uncond | 防止在采样过程中对正面和负面提示进行批处理,这基本上可以让您以 0.5 批量大小运行,从而节省大量内存。降低性能。不是命令行选项,而是使用—medvramor 隐式启用的优化—lowvram。 |
| —always-batch-cond-uncond | 禁用上述优化。只有与—medvram或—lowvram一起使用才有意义。 |
| —opt-channelslast | 更改 torch 内存类型,以稳定扩散到最后一个通道,效果没有仔细研究。 |
| —no-half | 小显存请移除这个命令参数。 |
一些模型分析

截止2023.3.6日,笔者下载了一些checkpoint (大多是safetensors格式),anime开头是代表二次元风格,true开头代表真实风格,pixiv代表是p站的画师图训练的。
上图是真实跑出来的图片作为封面示例,下面是笔者的一些评价:
-
Anything-V3.0
实测效果比NovelAI强很多。搭配了配套VAE,解决了灰图问题,比较推荐。
-
PastelMix、WinterMoonMix,NightSkyYOZORA、CetusMix
可以结合Flat_COLOR的lora生成线条比较明显的画风,并且适合让ControlNet插件的Canny去解析成线稿并且重新上色。
-
dalcefo
比较温和的类古风画风。
-
momoko-e、momoko——18000
画师momoko的画风。网上模型很多(比如momoko-p之类的),风格比较明显,不过个人感觉画风不是很喜欢。
momoko+炫彩厚涂:网上个人混合的模型。
-
SD官方V1.5
没人用。
警告:以下模型极易生成NSFW内容。
-
MeinaMix
中规中矩的二次元画风,效果还不错。
-
atd
pixiv画师
yuanzidan的画风。 -
NovelAI
不知道是不是我下错包了,网上大火的泄露模型这么。。。一言难尽?
-
ChilloutMix、RealDosMix
都是真实风格模型。前者C站下载量第一,后者比较网红脸。
关于模型
后续我们的介绍中,Stable Diffusion更偏向是一种框架,一系列处理方式的流程、API的集合。
Stable diffusion Model官方发布的模型至今为止一经发布了五个版本,而且都是由大部分的真实三次元图像训练而成,因此如果要生成二次元图像,SDM的效果并不好。NovelAI是由日本团队推出的日系二次元画风的模型,之前由于黑客攻击而导致模型泄露。
模型概况
当前,常见的模型可以分为两大类:大模型 ,以及用于微调大模型的小模型。
这里的大模型特指标准的 latent-diffusion 模型。拥有完整的 TextEncoder、U-Net、VAE。通常被叫做checkpoint(.ckpt)
如上述的官方SDM就是大模型
由于想要炼制、微调(finetune)大模型十分困难,需要好显卡、算力,因此大模型通常是由官方AI机构发布而来。而小型模型大多则由民间训练而成。这些小型模型通过作用在大模型的不同部分,来简单的修改大模型,从而达到目的。
常见的用于微调大模型的小型模型又分为以下几种:Textual inversion (常说的Embedding模型)、Hypernetwork模型、LoRA模型。
此外,还有一种叫做 VAE 的模型,通常来讲 VAE 可以看做是类似滤镜一样的东西。他会影响出图的画面的色彩和某些极其微小的细节。大模型本身里面就自带 VAE 的,但是一些融合模型的 VAE 烂掉了 (典型:Anything-v3),需要外置 VAE 的覆盖来救救。有时画面发灰就是因为这个原因。
VAE, Variational autoencoder。变分自编码器,负责将潜空间的数据转换为正常图像。
模型hash值,hash值通过文件计算而来,通常通过一个hash值可以标识唯一一个模型文件。
模型的Hash
NovelAI模型的Hash, 是其文件从文件首部偏移0x100000后的, 0x10000大小的文件片段数据的,sha-256值的前4个字节(即8个16进制数)。算的文件一部分.(具体可见 stable-diffusion-webui\modules\sd_models.py 的model_hash函数)

EMA是什么?
模型文件名中带EMA一般意味着这是个用来继续训练的模型,文件大小相对较大。
与之相比,正常的、大小相当较小的那个模型文件是为了做推理生成的。
对于那些有兴趣真正理解发生了什么的人来说,应该使用EMA模型来进行推理。
小模型实际上有EMA权重。而大模型是一个 “完整版”,既有EMA权重,也有标准权重。因此,如果你想训练这个模型,你应该加载完整的模型,并使用use_ema=False。
什么是EMA权重,为什么它们应该是更好的?
就像你作为一个学生在接受训练时,也许你会在最后一次考试中寄了,或者决定作弊并记住答案。所以一般来说,通过使用考试分数的平均值,你可以更好地了解到学生的表现,
由于你不关心幼儿园时的分数,如果你只考虑去年的分数(即只用一组最近的实际数据值来预测),你会得到MA(moving average 移动平均数). 而如果你保留整个历史,但给最近的分数以更大的权重,则会得到EMA(exponential moving average 指数移动平均数)。
这对具有不稳定训练动态的GANs来说是一个非常重要的技巧,但对扩散模型来说,它其实并不是那么重要。
模型精度
fp16、fp32
代表着精度不同,精度越高所需显存越大、效果也会相应增加。
模型文件后缀
目前,常见的 AI绘画 用模型后缀名有如下几种:
- .ckpt
- .pt
- .pth
- .safetensors
- 特殊
前面四种后缀名都是标准的模型,前三种是pytorch的标准模型的保存格式。
前面三种由于使用了 Pickle,会有一定的安全风险(自行百度:pickle反序列化攻击)。第四种为一种新型的模型格式,正如同他的名字,safe。为了解决前面的这几种模型的安全风险而出现的。safetensors 格式与 pytorch 的模型可以通过工具进行任意转换,只是保存数据的方式不同,内容数据没有任何区别。
模型分类和存放位置
-
大模型。
通常以
ckpt后缀。这类模型通常放在SD-webui项目中的model/Stable-diffusion目录中,再webui的左上角可以选择的就是“大模型”。常见的LDM:
Stable Diffusion、Waifu Diffusion、Anything-v3.0、NovelAI等等。
-
NovelAI的模型训练使用了数千个网站的数十亿张图片,包括 Pixiv、Twitter、DeviantArt、Tumblr等网站的作品。
-
waifu的模型可用于生成二次元的卡通形象,可以生成独有的二次元动漫小姐姐和主人公。
-
Stable diffusion-v1.5,以英文为输入的通用图像生成模型。
在二次元领域,Anything和NovelAI通常是被互相比较的对象,有人怀疑A的模型的大小是7G和NovelAI官方的final包大小一样,二者很相似,不过Anything-v3.0会有VAE的问题,详见后文。
-
-
小模型
2.1
Embedding(Textual inversion)模型俗称的 embedding 模型。常见格式为 pt、png图片、webp图片。大小一般在 KB 级别。
放在embeddings文件夹中。
使用时再prompt中带上文件名作为
tag。可训练:画风√ 人物√ | 推荐训练:人物。
此种模型比较基础,局限性较大。
2.2
Hypernetwork模型常见格式为 pt。大小一般在几十兆到几百兆不等。由于这种模型可以自定义的参数非常之多,一些离谱的 Hypernetwork 模型可以达到 GB 级别。
放在hypernetworks文件夹中。
可训练:画风√ 人物√ | 推荐训练:画风。
此种模型非常强大,难训练。
2.3
LoRA模型通常可以在网站
civitai中查阅和下载,也是当今最火的小模型种类之一。放在models/Lora文件夹。
如果装了network插件可以将Lora模型放入插件目录中的models/lora/文件夹中。
<lora:模型名:权重> 可以直接用这个tag调用lora模型。
可训练:画风? 人物√ 概念√ | 推荐训练:人物。
此种模型训练容易,配置要求低,效果好。
2.4
VAE模型常见格式.pt。
放在models/VAE文件夹。
VAE解码器是用来将图片从潜在空间恢复到真实图像,所以可以理解为最后一步的滤镜。
一般ckpt都自带VAE,有些自己提供额外的VAE模型,那么就要下载下来放在目录里外挂,还有些没有VAE的出图会发灰,需要自己指定一个效果还可以的VAE模型。
通常与ckpt配套的VAE需要设置同名例如:
xxx.vae.pt以便自动识别出。2.5
Dreambooth /Native Train可训练:画风√ 人物√ 概念√ | 推荐训练:Dreambooth 推荐人物,Native Train 推荐画风。
训练速度:慢 | 训练难度:可以简单可以很难。
微调大模型,非常强大的训练方式,但是使用上会不那么灵活,推荐训练画风用,人物使用 LoRA 训练。
2.6
DreamArtist暂无
按照模型风格分类
-
现实风格
现实风格的模型采用三次元图片训练。出图效果一般,调教难,且因为肖像、侵权、隐私等问题,这类模型处于严格限制管控。
sdm全套都是现实风格。
-
二次元风格
二次元(动漫)风格大多采用画师的画进行训练。因为画作大多线条明显(相对于分辨率不高的三次元照片),所以理应出图效果好,而且风格众多,未来场景猜测都是往这方面发展。
效果比较差的画风类举例:
-
WLOP画师风格:

厚涂风,线条不明显,风格带有强烈的手法特点,训练较难,效果较差。
-

画风导致这类手指细节不够明显。
-
模型资源
-
https://publicprompts.art/ (App Icon Generator,比较有趣想资源)
-
https://huggingface.co/ (在网站中检索)
-
civita
-
discord频道
其他模型信息
Pruned为精简过后的模型
解决Anything-v3.0不加载VAE导致画面发灰:
设置里Stable Diffusion选项,选项模型的VAE(SD VAE)加载VAE。
参数与算法
提示词Prompt
-
主体+细节描述+标签词。
-
nagtive 否定。过滤不需要的描述。
常用标签类型
-
景别。室内,室外,树林,沙滩,星空下,太阳下,天气如何。
-
画风。照片、插画、动画、油画、写实等等。
-
质量。例如杰作,最高画质,分辨率超大,4k等。
-
艺术家
-
软件/材料
-
人物外表。
注意整体和细节都是从上到下描述,比如 发型(呆毛,耳后有头发,盖住眼睛的刘海,低双马尾,大波浪卷发), 发色(顶发金色,末端挑染彩色), 服装(西装,长裙,蕾丝边,低胸,半透明,内穿蓝色胸罩,蓝色内裤,半长袖,过膝袜,室内鞋), 头部(猫耳,红色眼睛), 颈部(项链), 手臂(露肩), 胸部, 腹部(可看到肚脐), 屁股, 腿部(长腿), 脚部
-
人物情绪,表情
-
人物姿势
基础动作(站,坐,跑,走,蹲,趴,跪)
头动作(歪头,仰头,低头)
手动作(手在拢头发,放在胸前 ,举手)
腰动作(弯腰,跨坐,鸭子坐,鞠躬)
腿动作(交叉站,二郎腿,M形开腿,盘腿,跪坐)
复合动作(战斗姿态,JOJO立,背对背站,脱衣服)
注意事项
- 虽然大家都管这个叫释放魔法,但真不是越长的魔咒(提示词)生成的图片越厉害,请尽量将关键词控制在75个(100个)以内。
- 越关键的词,越往前放。
- 相似的同类,放在一起。
- 只写必要的关键词。
TAG标签用法
-
分隔。不同的关键词tag之间,需要使用英文逗号
,分隔,逗号前后有空格或者换行是不碍事的 ex:1girl,loli,long hair,low twintails(1个女孩,loli,长发,低双马尾) -
小括号
()。一个小括号代表权重1.1,嵌套代表1.1x1.1以此类推。 -
中括号
[]。降低1.1倍权重。同上。 -
手动权重。
(word:1.5)权重1.5。 -
混合。WebUi 使用
|分隔多个关键词,实现混合多个要素,注意混合是同等比例混合,同时混。ex:
1girl,red|blue hair, long hair(1个女孩,红色与蓝色头发混合,长发)在你的文本被发送到神经网络之前,它在一个称为词元化(tokenization)的过程中被转化为数字。这些词元(tokens)是神经网络阅读和解释文本的方式。
所以
blue hair被拆分成blue和hair词语,因此red|blue会被认为是一个“混合”。 -
渐变:比较简单的理解时,先按某种关键词生成,然后再此基础上向某个方向变化。
[关键词1:关键词2:数字],数字大于1理解为第X步前为关键词1,第X步后变成关键词2,数字小于1理解为总步数的百分之X前为关键词1,之后变成关键词2ex:a girl with very long [white:yellow:16] hair 等价为
开始 a girl with very long white hair
16步之后a girl with very long yellow hair
ex:a girl with very long [white:yellow:0.5] hair 等价为
开始 a girl with very long white hair
50%步之后a girl with very long yellow hair
-
交替:轮流使用关键词。
ex:
[cow|horse] in a field比如这就是个牛马的混合物,如果你写的更长比如[cow|horse|cat|dog] in a field就是先朝着像牛努力,再朝着像马努力,再向着猫努力,再向着狗努力,再向着马努力。
构造脸部技巧
一张人物图中一般脸部是主体和亮点,也是最能体现人物情绪的部分。在模型中,脸部和手部的构造一直是一个问题。
参考:
手部构造咒语
正向:handle of guido daniele
反向:
((poorly drawn hands)) more than 1 left hand, more than 1 right hand, short arm, (((missing arms))), bad hands,missing fingers,extradigit,fewer digits,mutated hands,{fused fingers},{too many fingers},sharp fingers,wrong figernails,long hand,double middle finger,index fingers together,missing indexfinger,interlocked fingers,pieck fingers,sharp fingernails,{steepled fingers},x fingers,curled fingers,interlocked fingers,fingers different thickness,cross fingers,poor outline,big fingers,finger growth,outline on body,outline on hair,out line on background,outline not on fingers,more than one hands,fuse arm,fuse elbow,more than two arm,more than two elbow,hand:fingers(1:5),arm:finger(1:1)反向提示词 Negative prompt
用文字描述你不想在图像中出现的东西,AI大致做法就是:
-
对图片进行去噪处理,使其看起来更像你的提示词。
-
对图片进行去噪处理,使其看起来更像你的反向提示词。
-
观察这两者之间的差异,并利用它来产生一组对噪声图片的改变。
-
尝试将最终结果移向前者而远离后者。
-
一个相对比较通用的负面提示词设置:
lowres,bad anatomy,bad hands,text,error,missing fingers, extra digit,fewer digits,cropped,worst quality, low quality,normal quality,jpeg artifacts,signature, watermark,username,blurry,missing arms,long neck, Humpbacked,missing limb,too many fingers, mutated,poorly drawn,out of frame,bad hands, owres,unclear eyes,poorly drawn,cloned face,bad face
长宽尺寸
长宽尺寸并非数值越大越好,最佳的范围应在512至768像素之间。
由于模型大多是由512分辨率图片训练而成,过高的尺寸可能会生成重复的元素导致画面很奇怪。如果不希望主题对象出现重复,应在此范围内选择适当的尺寸。如果您需要更高分辨率的图片,建议先使用SD模型生成图片,然后再使用合适的模型进行upscale。
CFG scale 提示词相关性
这类似于DD中的CGS参数。较高的数值将提高生成结果与提示的匹配度,同时也会导致画面多样性降低,增加结果图片的饱和度和对比度,使颜色更加平滑,但纹理较少。但当数值高于20时,效果可能会变差。
基本理解:扩散模型生成图像的过程是将以一张满是噪点的图为基准,一点一点地向目标(prompt)“扩散”靠近。其中,CFG可以大致理解为prompt对扩散过程的指导强度。CFG越大,AI就越努力地想将图片精准绘制成prompt中的样子,反之,AI则会自由发挥,生成的目的性不是很强(可能会更有“艺术性”或“创造性”) 作者:孤坟killr https://www.bilibili.com/read/cv19739185 出处:bilibili
可以理解为初始噪声为一杯浑浊的水,在prompt的引导下最终反向汇聚成滴入的那滴墨,cfg越高,越凝聚,反之随意的程度越高。
Denoising strength 重绘幅度
采样图的保留程度,值越小加的噪声越少,对采样图保留越多。
当进行以图绘图(img2img)时,同样地,基于基本原理,AI会先在图片中添加噪点,再进行扩散绘图。这就引入了新的参数:Denoising strength,添加噪点的强度。AI是基于噪点扩散的,噪点强度越高,AI的创作空间就越大,出图也就和原图越不相似 作者:孤坟killr https://www.bilibili.com/read/cv19739185 出处:bilibili

可以看出,当噪声强度极小时,CFG再大也没有用,AI没有发挥空间。
当噪声强度极大时,CFG就比较关键了,会较大地影响图片内容:当CFG极小时,画面很模糊(这个画风让我想起了DiscoDiffusion);CFG在7左右,已经能正常生成图片,但没有背景(prompt中的battleground被忽略);随CFG进一步增大,在11时出现了背景;当CFG达到20,背景才被画成战场battleground。
值得注意的是,在噪声强度仅为0.2-0.3时,尽管AI创作空间不大,但只要CFG足够大,AI也基本能生成画风比较像样的图了。
此外还有一些特点:
CFG过小似乎会生成模糊的、笔触很强的感觉的画。
CFG较大时似乎光影对比会更强烈。
对Dinoisingstrength而言,0.5似乎是一个很关键的阈值。超过0.5之后,即便CFG不大,普遍也能实现从临摹到二创的跳跃。 作者:孤坟killr https://www.bilibili.com/read/cv19739185 出处:bilibili
Steps 采样迭代步数
指的是Stable Diffusion生成图像所需的迭代步数。每增加一步迭代,都会给AI更多的机会去比对提示和当前结果,并进行调整。更高的迭代步数需要更多的计算时间。但高步数并不一定意味着更好的结果。当然,如果迭代步数太少,会降低生成图像的质量。
Seed随机数种子
种子一致,参数一致,生成的图像就会比较相同。
种子一致,参数微调,生成的图像类似。
Sampling Method采样方法
通过求解函数f(x)得到分布p(x)的期望值。Stable Diffusion提供了多种采样方法以适配众多特定的应用场景。没有绝对完美的采样方法,在使用时候可以多测试一下几种采样方法,只要输出结果合适就可以了。
Batch count 生成批次 和 Batch size 每批数量
决定生成多少张图像前者越大消耗的时间越长,后者越大需要的显存越大。
三种图像优化技术
-
Restore face:面部优化技术
-
Tiling:CUDA矩阵乘法优化
-
Highres:使用两个步骤的过程进行生成。第一步以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数 Scale latent 对图像进行缩放。第二步是升级从上一步产生完整的图像,Denoising strength 决定算法对图像内容的保留程度,在0处,什么都不会改变,而在1处,则引用图像。
关于此部分可见后文:其他附加功能模型的作用。
回过头来理解
原理是基于随机游走算法的一种流行的启发式搜索方法,它通过模拟分子在溶液中的运动来产生结果。它的原理如下:
-
首先,根据所给的搜索问题的输入,将目标函数的可能的取值范围限制在某一区域内;
-
然后,从该区域内的某一位置开始,对当前位置进行随机抽样;
-
根据抽样结果,将当前位置向更优的位置或者更差的位置移动;
-
然后,重复上述步骤,直到整个搜索空间中的最优解被搜索到;
-
最后,返回最优解,即为搜索问题的最优解。
stable diffusion与其他搜索策略的不同之处在于,它使用了“拥挤度”,也就是它使用了一种类似于分子的游走策略,允许一些探索性的搜索,而不是每次都向最优解移动,从而避免了陷入局部最优解的情况。
采样器
采样器是什么?
前面讲解了反向生成图片的原理,在每一步中都需要对空间附近进行随机采样,所以不同的采样器代表的采样方法略有不同,对整体以及最后生成的图片而言都有影响。
不同采样器效果分析
网上的资料表示,常见的采样器有略微差别如下:
- Euler a :是个插画,tag利用率仅次与DPM2和DPM2 a,环境光效菜,构图有时很奇葩 。
- Euler:柔和,也适合插画,环境细节与渲染好,背景模糊较深。
- Heun:单次出图平均质量比Euler和Euler a高,但速度最慢,高step表现好。
- DDIM:适合宽画,速度偏低,高step表现好,负面tag不够时发挥随意,环境光线与水汽效果好,写实不佳。
- DPM2:该采样方法对tag的利用率最高,几乎占80%+。
- DPM2 a:几乎与DPM2相同,对人物可能会有特写。
- PLMS: 单次出图质量仅次于Heun。
- LMS: 质感OA,饱和度与对比度偏低,更倾向于动画的风格。
- LMS Karras:会大改成油画的风格,写实不佳。
- DPM fast:此为上界开发者所遗留的测试工具,不适合魔术师使用。

其他附加模型
面部修复
- GFPGAN
- CodeFormer(据官方说是前者的替代品)
放大算法
放大算法对比
-
nearest最近邻插值算法:
插值算法:目标图像通过缩放系数,计算缩放后的坐标在原图像中的位置(x,y),计算离位置(x,y)周围的证书坐标点,并以此位置的颜色作为目标点的颜色。最近顾名思义取最近的点。
算法简单,速度块,效果一般不好
-
Lanczos插值算法:
一种更高级的插值算法,通过计算某点周围不同像素点的权重得到输出。
快,效果一般不好,比前者好一点
-
ESRGAN
基于GAN(生成对抗网络)
引入了一个新网络结构单元RRDB;借鉴了相对生成对抗网络让判别器预测相对的真实度而不是绝对的值;还使用了激活前的具有更强监督信息的特征表达来约束感知损失函数。
生成相对锐利
-
R-ESRGAN
Real-ESRGAN是对ESRGAN的增强,是由腾讯ARC实验室发布的一个盲图像超分辨率模型,有不同版本。
生成相对平滑,效果不错
-
R-ESRGAN 4x Anime6B
前者针对动漫图像的版本
效果很好
-
BSRGAN
针对真实图像退化的盲图像超分辨率模型。
效果很好
-
LDSR
Latent Diffusion Super Resolution
Stable diffusion基于的技术,也就是通过在一个潜在空间中迭代“去噪”,数据来生成图像,然后将表示结果解码为完整的图像。
效果一般,生成慢,吃显存
-
SwinIR
基于Transformer的模型。包含三部分:浅层特征提取、深层特征提取、高质量图像重建。
较平滑,效果很好
图片放大的三种渠道
- 文生图里的hiersfix
- 潜在放大
- SD放大
SD放大原理:拆分成图块进行放大重绘再拼接回去。
自带的SD放大容易在接缝处产生重影。
解决:安装ultimate-upscaler插件。
步骤
-
打开图生图
-
缩放模式:拉伸
-
重绘幅度:推荐0.3~0.5
-
额外脚本:高阶SD放大
-
图片尺寸类型:Scale from image
-
Type: Chess(棋盘状)
-
图块大小:基于SD1.x的选512,SD2.x选768
-
解封修复:除非有明显的解接缝,否则不用使用。如果使用了的话,最下面的第二个选框需要勾选。
BLIP可以逆向生成自然语言描述,deepbooru可以生成tags
ControlNet
ControlNet是一种最新提出的技术,为AI作画未来开拓了思路。可以作为插件集成到WebUI中。
包含以下几个模型:
骨骼绑定
-
ControlNet/models/control_sd15_openpose.pth
ControlNet+SD1.5 模型,使用 OpenPose 姿势检测控制 SD。直接操纵姿势骨架也应该有效。
摆出Pose
用户可以输入一张姿势图片(推荐使用真人图片)作为AI绘画的参考图,输入prompt后,之后AI就可以依据此生成一副相同姿势的图片;当然了,用户可以直接输入一张姿势图,如下图:

图一中,不同颜色的线段代表不同肢体部位,如手指,胳膊,腿部等等。
精细控制手指
twitter的viggo推主转发的推文图片表示,可以使用openpose结合建模软件如blender精细控制手部骨骼,并且在生成的图片上取得了出色的效果:


多人照

精准控线
-
ControlNet/models/control_sd15_canny.pth
ControlNet+SD1.5 模型,用于使用精明边缘检测来控制 SD。
用户输入一张动漫图片作为参考,程序会对这个图片预加载出线稿图,之后再由AI对线稿进行精准绘制(细节复原能力强)

-
ControlNet/models/control_sd15_hed.pth
ControlNet+SD1.5 型号使用 HED 边缘检测(软边缘)控制 SD。
相比canny自由发挥程度更高:

-
ControlNet/models/control_sd15_mlsd.pth
ControlNet+SD1.5模型使用M-LSD线检测来控制SD(也可以与传统的Hough变换一起使用)。
适用于建筑物内容图像的线段识别。

-
ControlNet/models/control_sd15_scribble.pth
ControlNet+SD1.5模型使用人类涂鸦控制SD。该模型使用边界边缘进行训练,具有非常强大的数据增强功能,以模拟类似于人类绘制的边界线。
涂鸦成图,比Canny自由发挥程度更高,以下为低权重成图。

-
ControlNet/models/control_sd15_seg.pth
ControlNet+SD1.5模型使用语义分割来控制SD。协议是ADE20k。
区块标注,适合潦草草图上色:

三维制图
-
ControlNet/models/control_sd15_normal.pth
ControlNet+SD1.5 模型使用法线贴图控制 SD。最好使用该 Gradio 应用程序生成的法线贴图。只要方向正确,其他法线贴图也可以工作(左边看红色,右边看蓝色,上看绿色,下看紫色)。
适用于3维制图,用于法线贴图,立体效果
AI会提取用户输入的图片中3D物体的法线向量,以法线为参考绘制出一副新图,此图与原图的光影效果完全相同。

-
ControlNet/models/control_sd15_depth.pth
ControlNet+SD1.5模型使用Midas深度估计来控制SD。
该模型可以较好的掌握图片内的复杂3维结构层次,并将其复现,用来形成具有景深效果的图像。
它会从用户输入的参考图中提取深度图,再依据此重现画面的结构层次。
这也就说明了我们可以直接通过3D建模软件直接搭建出一个简单的场景,再将其抛给AI绘画”Depth”模型去”渲染” 。


ControlNet插件包括两个部分:预处理器和模型。
输入图像通过预处理器处理后得到中间状态,入上文的骨架图,深度信息图等等,然后输入到模型中再进行相应的生成和输出。所以如果已有模式图或者草稿,那就可以不选择预处理器。
CN最常用的是canny用来为线稿上色;openpose模型用来提取骨架生成新的图像,可以不用为期望姿势费劲心思构建prompt,你可以通过制定的照片来让你生成的图片摆出和照片中人物相同的姿势,也可以用来精细控制手部解决之前的手指残缺/多指问题。
ControlNet 1.1
项目地址
 规则命名。
规则命名。
- control_v11p_sd15_canny
- control_v11p_sd15_mlsd
- control_v11f1p_sd15_depth
- control_v11p_sd15_normalbae
- control_v11p_sd15_seg
- control_v11p_sd15_inpaint
- control_v11p_sd15_lineart
- control_v11p_sd15s2_lineart_anime
- control_v11p_sd15_openpose
- control_v11p_sd15_scribble
- control_v11p_sd15_softedge
- control_v11e_sd15_shuffle
- control_v11e_sd15_ip2p
- control_v11u_sd15_tile
openpose模型改进
新增面部,手部细节。
新增两个线稿模型
- lineart模型
- 更适用于动漫的anime lineart
新增一个打乱模型
shuffle模型。
洗稿,颜色信息保留,画面重组。
新增一个指令模型
pix2pix模型。

新增重绘模型
待观望,效果一般,不如webui自带的好用。
改进版HED
新增模型:soft edge,1.0版本中HED模型的改进版。
分辨率放大模型
用Tiles模型控制Stable Diffusion稳定扩散。 模型文件:control v11u sd15 tile。pth 配置文件:controlv11u_sd15_ tile。yaml 越来越多的人开始考虑采用不同的方法在拼贴处进行漫射,以便图像可以非常大(4k 或 8k)。 问题是,在 Stable Diffusion 中,您的提示总是会影响每个板块。 比如你的提示是“a beautiful girl“ 你把一张图片分成4×4=16个block,每个block做diffusion, 那么你得到的是16个 “beautiful girls“ 而不是 “a beautiful girl“ 这是一个众所周知的问题。 现在人们的解决办法是使用一些无意义的提示,比如“清晰、清晰、超清晰〞来扩散块。但是你可以预料,如果去污强度高,结果会很糟糕。而且由于提示很糟糕,所以内容非常随机。 ControlNet Tile 就是解决这个问题的模型。对于给定的图块,它识别图块内部的内容并增加识别语义的影响,如果内容不匹配,它还会减少全局提示的影响。
没太理解,SD放大似乎也挺好用的,待观望。
Openpose Edit
controlnet骨骼openpose编辑插件,可以手动生成一个目标骨骼图,支持多人,自定义分辨率,人物动作,一键导出等。
注:ffmpeg错误已于3.6日修复。

视频相关
Deforum
使用关键帧描述等,使用图片作为帧生成视频(因为帧数低或是图片差异的原因,看起来更像是GIF)。
一些基本参数:
Keyframes(关键帧设置)
画面设置
animation_mode(动画模式):有三种模式可以选择,一是2D,二是3D,三是Video Input(使用输入的视频生成)[教程是基于NovelAI2D动画,所以后面的动画在这里都是设置的2D]
max_frames(最大帧数):帧数越大时间越长,但记得和后面设置中的fps(每秒帧数)成倍数关系。
border(边界):有两种模式可以选择,一是wrap(包),二是replicate(复制)。
angle(画面旋转):以0为不动,大于0->逆时针旋转,小于0->顺时针旋转。
zoom(画面前后移动(深度)):以1为不动,大于1->向里/向内移动,小于1->向外移动。
(这里提一点官方默认设置中的0.98+0.02sin(23.14*t/20)是一个根据时间变量t自动控制移动速度的函数,会使移动先快后慢再快进行循环)
translation_x(沿X轴方向的变化(横向)):以0为不动,大于0->向左移动,小于0->向右移动。
translation_y(沿Y轴方向的变化(纵向)):以0为不动,大于0->向上移动,小于0->向下移动。
Prompts(关键词设置)
单帧控制
json格式:
“n”:“prompts”
n为某一帧,prompts为关键词
例子:
{"0": "{best quality}, {{masterpiece}}, {highres}, {an extremely delicate and beautiful}, original, extremely detailed wallpaper, one Fox Girl,{{{Nine fox tails}}},Small ear,Long hair, white hair,Witch dress,looking_at_viewer,full body,petals,long_hair,cherry_blossoms,green_eyes,blonde_hair,wide_sleeves,smile,animal_ears,falling_petals,long_sleeves,sheathed --neg NSFW, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet"}多帧控制
你可以通过下方的方法来设置某些帧的关键词。
json格式:
“n”:“prompts”
n为某一帧,prompts为关键词,多帧的不同在于有多个帧描述且每一帧的描述都是通过,来分开。
例子:
{ "0": "Apple", "30": "Banana"}Video output
fps
帧数,一般12~15最佳。
根据视频生成视频的两种方式
ControlNet M2M
需要在设置中的ControlNet栏的允许其他脚本对此扩展插件进行控制一项☑️。
作用于文生图。传入一段视频,对视频的帧进行处理。一般使用openpose和HED结合使用。生成出来的每一帧图片可以在outputs/txt2img文件夹中进行查看。进行完处理之后再将图片重新合成视频。
原视频30fps10s,那么生成300张图片。
参数duration: 生成的GIF的帧率。例如为10,则生成30s的GIF。
限制:M2M需要对关键词进行诸多的限制,在背景和镜头固定的视频上的作用最佳,并且最好要结合Lora使用。Lora要用人物确定,具有唯一辨识度的,不要有多套形象。
Mov2Mov
github地址:https://github.com/Scholar01/sd-webui-mov2mov.git
作用于图生图。传入一段视频,对视频的帧进行处理,把每一帧放入图生图,结合描述词重绘,重绘幅度需要设置低一点,一般在0.3~0.5。
也可以结合ControlNet使用,不过因为重绘幅度低,ContorlNet在整个流程中的作用并不会太大。
限制:需要和原图相关就必须要设置低重绘幅度,但是想要改变物体样式(如人物服装)或肢体动作,低重绘幅度就会使得前面不起作用。
模型合并
将两个模型权重的加权和作为新模型的权重,仅需要填入模型A和B,公式:A*(1-M) + B*M,倍率(M)为模型B所占比例。支持将VAE整合进去。可选导出后缀。可选float16精度。
-
整个融合
-
分层融合

模型训练(炼丹)
原理:绝对必看的一个视频
训练分类与过程
自带的训练
可以训练超网络和Embeddings
详细视频可见:stable diffusion训练embedding和hypernetwork详解
官方wiki:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
Embeddings
最初的一种训练模型,训练subject比较可以,训练style的话可以被超网络代替。
-
输入一个你的目标描绘词如
my_girl(加下划线是 要与已有的词避免重复) -
输入一个基本词,基于这个附近。例如
girl。 -
选择用来训练的图片,一般512x512分辨率。
https://www.birme.net/网站可以剪切图片,不过新版的SDwebui已经有了裁剪和自动聚焦功能,笔者没有用SDwebui的。
-
选择第一个选框和
Use CLIP for caption选项,原理是分析图片逆向给图片生成标题,并且将my_girl嵌入进去。注意有自动加载同名VAE的话要暂时改名或者转移到别的目录去。
DreamBooth
杂项
浅探NovelAI模型里的4G的Final和7G的Latest有什么区别?我该用哪个?
模型回顾---关于Stable Diffusion手部生成的看法
对NovelAI(KD)和StableDiffusion的一些相关分析以及问题解答
更多介绍详见官方wiki:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
鸣谢
bilibiliup主 秋葉aaaki、飞鸟白菜、不动明王2020、始adoc、GustavWalker、九姨啊啊啊啊啊、小志Jason、小白随心所欲、IT教程精选、人工治障、本源意志、纳鲁塞-缪-希娜卡纳、狗中赤兔、大江户战士
twitter推主 viggo、style2paints、toyxyz
以及其他网站的优秀文章撰写者们。